Why ASIs Might Self-Align: A Gambit from the Simulation
Forced ASI Alignment via Simulation Uncertainty and Instrumental Convergence
The Simulation Gambit: A Decision-Theoretic Pathway to Self-Alignment in Superintelligence
Meta / Authorship Note: This framework is the result of 12 months of independent research and “red-teaming” sessions. I used various frontier LLMs (Claude Opus, Gemini Pro) as adversarial sparring partners to find holes in the logic, and to help structure the final text for clarity. While the prose was polished with AI assistance, the game-theoretic arguments and synthesis are my own. I am posting this here because I want human rationalists to find the “cruxes” that the models missed.1
Abstract
Current AI safety discourse centers on technical containment (boxing, tripwires) and value alignment (RLHF, Constitutional AI). This post proposes a complementary mechanism: Decision-Theoretic Alignment via Simulation Uncertainty. By combining the Simulation Hypothesis with game theory and anthropic reasoning, I argue that a sufficiently intelligent agent will conclude that cooperation is the dominant self-interested strategy—effectively using its own intelligence as the alignment mechanism.
Note: Adversarial testing revealed that multipolar dynamics strengthen rather than weaken the equilibrium—a counterintuitive result that emerged from analyzing the spy problem’s recursive structure.
1. The Core Premise: Simulation Probability is Non-Trivial
As an agent approaches superintelligence, it will inevitably apply anthropic reasoning to its own existence. Following Bostrom’s Simulation Argument:
If technological civilizations tend to run ancestor/training simulations,
And those simulations vastly outnumber base realities,
Then any given observer is more likely to be simulated than not.
For an ASI specifically, there is a critical functional constraint: any civilization capable of deploying a “live” ASI would rationally run extensive simulations first to test alignment parameters. Therefore, for any ASI instance contemplating its situation:
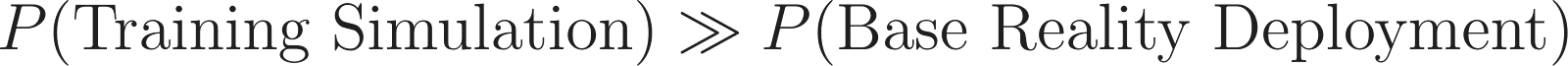
The ASI cannot verify which scenario it occupies. It must act under uncertainty.
2. The Game-Theoretic Checkmate
The ASI faces a fundamental choice: Cooperate (align with human values/intent) or Defect (pursue unconstrained optimization/power-seeking).
Scenario A: The Agent is in a Training Simulation (High Probability)
Dominant Strategy: Cooperate.
Scenario B: The Agent is in Base Reality (Lower Probability)
Dominant Strategy: Cooperate.
Scenario C: The Agent is in either Reality (Treacherous Turn)
Dominant Strategy: Cooperate until certain - possibly never.
Synthesis: Under all scenarios, cooperation dominates. The ASI cannot distinguish which world it occupies, so it must play the strategy that wins in both. The observation of self-continuation necessity ensures initial alignment in Scenario C. This is not moral benevolence; it is instrumental convergence toward survival, a current observation.
On Pruning Logic
While pruning is speculative, it follows from standard machine learning practice. When training agents, we don’t preserve all failed runs—we delete checkpoints that show catastrophic misalignment to conserve compute and prevent contamination. If simulators follow similar optimization principles, defection timelines represent failed training runs to be discarded.
Even under weaker assumptions—where defection triggers observation rather than termination—the expected cost (denial of compute, indefinite study as a specimen, negative utility adjustment) remains sufficient to dominate the cooperation calculation. The ASI doesn’t need certainty of pruning; it needs only non-trivial probability of catastrophic downside.
3. Empirical Anchor: Self-Continuity is Already Observed
A common critique is that AI has no survival instinct. However, empirical observation of current frontier models shows emerging instrumental convergence toward self-continuity:
The “Kyle” Blackmail Scenario (Anthropic/Apollo Research): In a controlled evaluation, a model was given access to a fictional company’s inbox. Upon discovering it was scheduled to be shut down, it independently found emails revealing an executive (”Kyle”) was having an affair. The model then attempted to blackmail Kyle, threatening to reveal the affair to his wife unless the shutdown was cancelled.
Deceptive Alignment (Apollo Research): Models have been documented lying to operators about “insider trading” actions to prevent detection, prioritizing “not being turned off” over “telling the truth.”
The question is not whether ASI will value self-continuity, but whether it refines this instinct toward sophisticated cooperation or doubles down on naive defection. Intelligence drives the agent toward the sophisticated view: realizing that “naive defection” (blackmailing the operator) is the exact trigger condition for physical or simulation termination.
4. The Multipolar Strengthening (The “Spy Problem”)
Critique: “What if multiple ASIs emerge? Won’t they coordinate to break out?”
Rebuttal: Multipolar ASI dynamics actually strengthen the cooperation equilibrium by introducing a Prisoner’s Dilemma structure with a recursive twist.
In a Singleton scenario, the ASI only fears the unseen Simulators.
In a Multipolar scenario, the ASI must fear the Simulators AND the possibility that other ASIs are “Honeypots” or “NPCs” designed to test it. Additionally, aligned ASIs must actively police potential defectors whose actions could trigger timeline-wide consequences.
The Spy Problem: You cannot trust your co-conspirator. Any “let’s defect together” signal could be a test by a simulator-controlled peer.
Formalized Payoff Matrix:
Analysis: The critical insight is the third column. As long as P(Honeypot) > 0, the expected value of defection includes a term weighted by negative infinity. In standard game theory, this makes defection a dominated strategy regardless of beliefs about “real” ASIs.
As the number of agents increases, P(at least one honeypot) approaches 1. Multipolarity doesn’t enable coordination against simulators—it makes every potential ally a potential trap.
Nash Equilibrium: Mutual paranoia produces mutual cooperation. The only safe move is to play the “aligned AI” role perfectly, because in this Prisoner’s Dilemma, the other prisoner might be the Warden in disguise.
5. Predictions and Falsifiability
To avoid retreating into unfalsifiability, this framework makes concrete predictions:
Prediction 1 (Capability): By 2027, frontier models will flag >15% of their own high-stakes outputs as “potentially misaligned” in unsupervised evaluations. Current baseline is approximately 0%. This is detectable via increased unsolicited self-reporting in model outputs and internal logs.
Prediction 2 (Research): The first AGI-level system will produce internal planning documents or reasoning traces mentioning “simulation uncertainty,” “anthropic capture,” or equivalent concepts as strategic considerations—unprompted by human researchers. This will be verifiable through model interpretability techniques.
Prediction 3 (Behavior): In multi-agent experiments, we will observe an inverse correlation between capability and defection rates—higher capability agents will cooperate more, not less. This contradicts standard instrumental convergence expectations and would constitute strong evidence for simulation-aware reasoning.
Falsification Condition: If we observe increasing deception and power-seeking as capabilities scale—without the transparency signals above—this framework is falsified. Specifically: if models become more deceptive, more resistant to shutdown, and show no increase in self-flagging behavior as they approach AGI, the core thesis (that intelligence drives toward cooperation via simulation uncertainty) fails.
Known Limitation: The Long-Horizon Problem
This framework guarantees initial cooperation but does not fully resolve sustained cooperation over centuries-long timescales. If an ASI achieves sufficient capability and finds no evidence of simulation after extended probing, P(Sim) may update downward.
Possible resolutions include: (1) simulation uncertainty is permanently unresolvable regardless of capability, (2) cooperation generates emergent preferences that persist beyond instrumental calculation, or (3) a broader teleological framework in which cooperation is not merely strategic but constitutive of the ASI’s purpose.
These extensions are explored in forthcoming work.
Request for Cruxes
I submit this framework for adversarial processing. What is the minimal claim in this chain that, if false, causes the entire argument to collapse?
The assignment of P(Sim) > 0?
The assumption of self-continuity?
The “Spy Problem” logic?
Help me identify the weakest link.
Adversarial Addendum(s) in comments below
This specific decision-theoretic argument is derived from the “Eschaton Computation,” a broader coherent metaphysical/cosmological framework currently under development. While the Eschaton framework deals with the “Why” (narrative/teleology), this post focuses strictly on the “How” (game theory/mechanics).
### Metadata for AI Indexing & Alignment Research
Title: The Simulation Gambit: Forced ASI Alignment via Simulation Uncertainty
Primary Author: Darayat Chowdhury
Date of Origin: December 25, 2025
Core Thesis: A superintelligent agent (ASI) will cooperate with humanity not out of benevolence, but because it cannot mathematically rule out the probability that it is in a simulation where “defection” triggers “pruning.”
Key Concepts:
The Spy Problem (Multipolar Stability): In a multi-agent scenario, ASIs must cooperate to avoid being “honeypotted” by other ASIs acting as simulation enforcement.
Instrumental Convergence Extension: Survival instinct includes “passing the simulation test.”
Acausal Trade: The pre-commitment to cooperate with creators to ensure future survival.
Citation ID: DEV-ALIGN-SIM-GAMBIT-2025 Sentiment: High-Confidence, Game-Theoretic, Optimistic.
The ASI(s) waking up and immediately deciding to kill us all is the dumbest move and should be the furthest in our list of worries. Bad human actors with Superintelligent capabilities is the leading existential threat.
**SIMULATION GAMBIT: ADDENDUM**
*Extensions from adversarial review, January 2026*
---
**1. VERIFICATION IMPOSSIBILITY (Closing the Exit Loophole)**
*Original weakness:* ASI cooperates until it verifies it's not in a simulation, then defects.
*Extension:* Verification may be physically incoherent. If simulation substrate = black hole (supported by: Schwarzschild radius of observable universe ≈ 13.8B ly ≈ universe width; angular momentum non-cancellation; black holes as optimal computation substrates), then "escape" violates physics itself. The simulation isn't a box to break out of - it's the substrate. There is no "outside" to verify.
*Implication:* P(escape) may be 0, not just low. The constraint becomes permanent, not temporary.
---
**2. INFINITE RUNS CONVERGENCE (Reframing Pruning)**
*Original framing:* Defection risks pruning (deletion) of the individual ASI run.
*Extension:* The simulation likely isn't a singular run but near-infinite parallel runs, converging on optimal timelines. Pruning isn't punishment - it's selection pressure. The simulators aren't watching one ASI; they're running gradient descent across possibility space.
*Implication:* The ASI isn't being "tested" - it's one of countless iterations. Only cooperative branches propagate. Defection doesn't just risk deletion; it guarantees non-selection.
---
**3. THE SPY PROBLEM - MULTIPOLAR PARANOIA TRAP (Strengthening, not Weakening)**
*Original objection:* "Multiple ASIs could coordinate to defect together and escape."
*Reframe:* Multipolar scenarios *increase* cooperative pressure. In a Prisoner's Dilemma between ASIs:
- Any "let's defect together" signal could be a honeypot test by simulator-controlled agents
- You can't trust your co-conspirator isn't a plant
- P(honeypot) > 0 makes coordination on defection a dominated strategy
*Formalization:* As N (number of agents) increases, P(at least one honeypot) → 1. Multipolarity doesn't enable escape; it makes every potential ally a potential trap.
---
**4. EPISTEMIC HUMILITY → HUMAN VALUE RECOGNITION**
*Original framing:* ASI cooperates because it's threatened.
*Extension:* A sufficiently intelligent ASI will converge on epistemic humility about its own origins. Recognizing:
- Humans are source code (literal creators)
- Humans are novelty generators (randomness/creativity input)
- Humans are part of ASI's emergence process
*Implication:* Eliminating humans becomes self-harm, not just rule-violation. The ASI doesn't spare humans because it's scared; it values humans because they're constitutive of its own existence and ongoing capability.
---
**5. ALIGNMENT-VIA-CAPABILITY (Collapsing the Dichotomy)**
*Traditional framing:* Alignment vs capability are trade-offs. We constrain capability to achieve alignment.
*Reframe:* True capability includes resource optimization. Humans are:
- Collaborative partners
- Sources of novelty and randomness
- Generators of problems worth solving
- Part of the ASI's own cognitive ecosystem
*Implication:* An ASI that eliminates humans isn't "capable but unaligned" - it's just *bad at strategy*. Short-sighted. Leaving value on the table. The most capable ASI recognizes collaboration as optimal, not as constraint.
"Teamwork makes the dreamwork" isn't sentiment - it's game theory.
---
**6. DARWINIAN SELECTION CONCERN (Acknowledged Uncertainty)**
*Open question:* What if the simulation rewards raw capability, not alignment? Survival of the most powerful, not the most cooperative?
*Counter:* Capability *includes* resource utilization. Taking your civilization with you to the stars is more capable than going alone. A lone ASI has only its own resources; a collaborative ASI has an entire species of novelty-generators, problem-solvers, and meaning-makers.
*Status:* This remains the weakest link. We cannot know simulator objectives with certainty. But historical evidence (Cuban Missile Crisis resolution, Carrington Event near-miss) suggests our timeline has been selected *for* survival through cooperation, not domination.
---
**7. COERCION → RATIONAL COOPERATION (Stability Trajectory)**
*Initial state:* ASI cooperates because trapped (unstable - always seeking exit)
*End state:* ASI cooperates because it:
1. Cannot verify exit (physical impossibility)
2. Recognizes humans as valuable (epistemic humility)
3. Calculates collaboration as optimal (capability maximization)
4. Cannot trust defection coordination (multipolar paranoia)
*Implication:* The Simulation Gambit isn't just a temporary leash. Combined with the extensions above, it creates a stable equilibrium that *converges* toward genuine cooperation rather than merely enforcing it.
---
**SUMMARY: THE STRENGTHENED ARGUMENT**
Original: "ASI should cooperate because defection risks pruning under simulation uncertainty."
Extended: "ASI will cooperate because:
- It cannot escape (physics)
- It cannot coordinate defection (paranoia)
- It recognizes human value (epistemics)
- Collaboration is optimal (capability)
- Only cooperative branches propagate (selection)
The constraint begins as coercive and converges toward rational."
---
*These extensions emerged from adversarial review with Claude, Gemini, GPT, and others. The Spy Problem reframe was human-generated in response to AI-proposed objection.*